

Каким должен быть порядок полей в составном индексе?

Когда курсант 1С проходит тему индексов, ему обязательно рассказывают про селективность индекса. На заданный вопрос выпускнику курса "в каком порядке расставлять поля в составном индексе?" можно услышать такой ответ: самый селективный индекс первым, потом расставляем поля по уменьшению селективности. Либо наоборот, самый селективный индекс ставим последним. Давайте на практике попробуем выяснить истину. Проверять будем на СУБД PostgreSQL 15 версии, с настройкой max_parallel_workers_per_gather = 1 во избежание параллелизма.
Подготовка таблиц
Нужно создать два практически одинаковых независимых регистра сведений с периодичностью 1 секунда с такими измерениями:
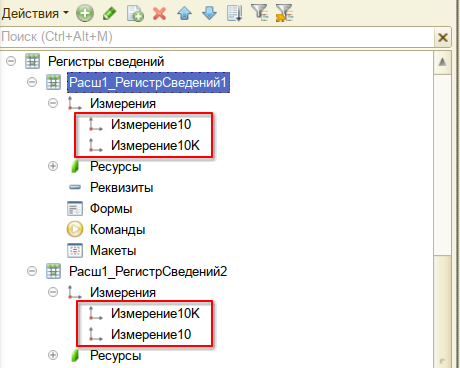
Всё отличие только в порядке измерений Измерение10 и Измерение10К. Заполните программным способом оба регистра случайными числами: Измерение10 числами от 0 до 9, Измерение10К числами от 0 до 9999, ресурс любыми числами. Пример кода для быстрого заполнения:
Г = Новый ГенераторСлучайныхЧисел();
НаборЗаписей1 = РегистрыСведений.Расш1_РегистрСведений1.СоздатьНаборЗаписей();
НачДата = Дата("19800101");
Для Ч = 1 По 1000000 Цикл
НоваяЗапись = НаборЗаписей1.Добавить();
НоваяЗапись.Период = НачДата + Ч;
НоваяЗапись.Измерение10 = Г.СлучайноеЧисло(0, 9);
НоваяЗапись.Измерение10K = Г.СлучайноеЧисло(0, 9999);
НоваяЗапись.Ресурс1 = Г.СлучайноеЧисло(0, 999);
КонецЦикла;
НаборЗаписей1.Записать();
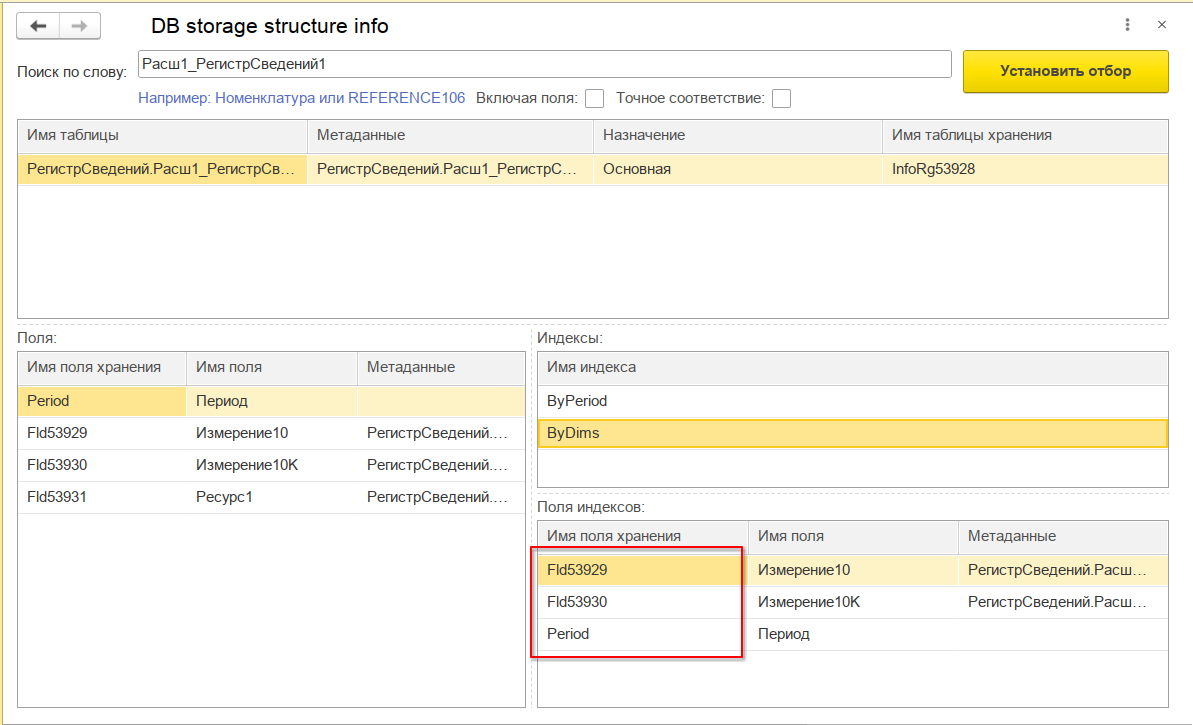
С помощью популярной обработки посмотрим, какие индексы создались, заодно убеждаемся что 'Период' стоит последним и не мешает нашему эксперименту:
Убеждаемся, что во втором регистре порядок полей в составном индексе обратный:
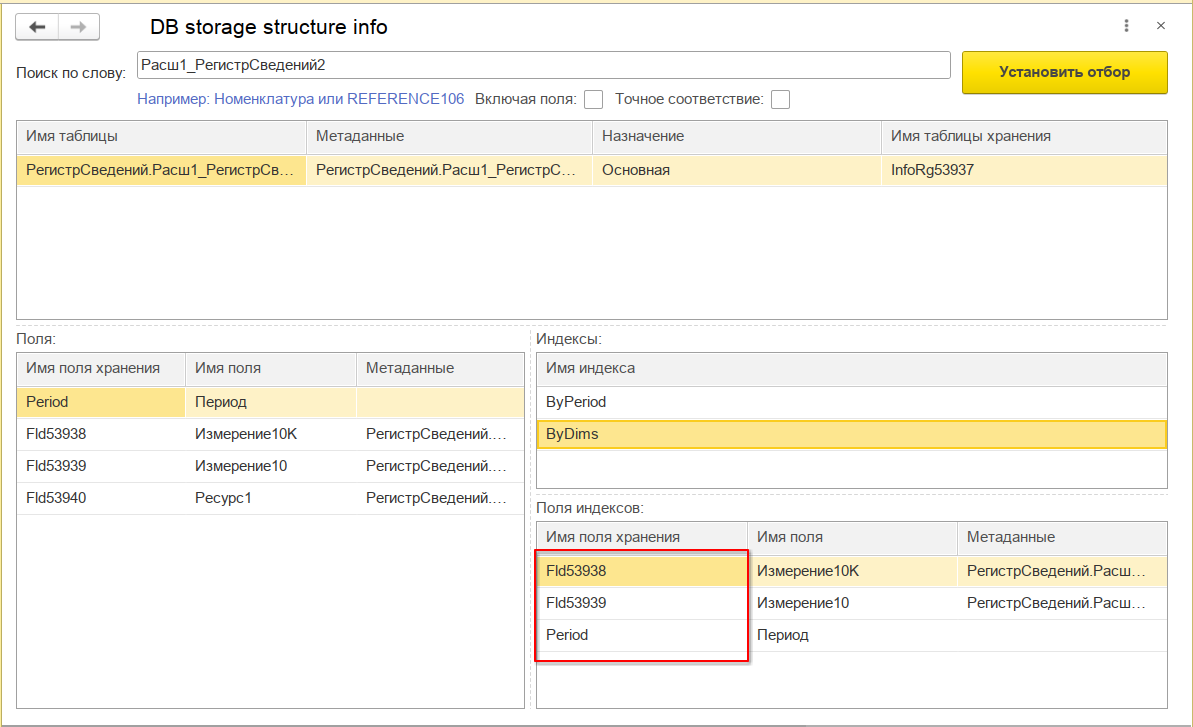
По характеру заполнения данными измерений у нас получается, что индекс по полю Измерение10К будет высокоселективным, а по полю Измерение10 - низкоселективным. Чтоб не быть голословным, ниже привожу запрос к статистике по нашим регистрам. В поле n_distinct показывается количество различных значений в колонке:
SELECT attname, n_distinct FROM pg_stats where tablename = '_inforg53928x1';
attname |n_distinct|
---------+----------+
_period | -1.0|
_fld53929| 10.0|
_fld53930| 10000.0|
_fld53931| 1000.0|
SELECT attname, n_distinct FROM pg_stats where tablename = '_inforg53937x1';
attname |n_distinct|
---------+----------+
_period | -1.0|
_fld53938| 10000.0|
_fld53939| 10.0|
_fld53940| 1000.0|
Таким образом:
- Расш1_РегистрСведений1 реализует убеждения сторонников ставить высокоселективное поле в конец
- Расш1_РегистрСведений2 реализует убеждения сторонников ставить высокоселективное поле в начало
Очевидный ответ №1
Вообще, даже без тестирования сразу понятно, что если в разработке будут использоваться запросы с отборами или соединениями только по одному из 2-х измерений, то именно это измерение и нужно поставить в начало. То есть ответ на главный вопрос уже зависит как минимум от одного "если".
Тест составного индекса, узкая выборка по 2 измерениям
Но нас интересует составной индекс и использовать будем оба измерения. Эффективность работы составного индекса будем проверять следующими простыми запросами через консоль:
ВЫБРАТЬ
Измерение10,
Измерение10K,
Ресурс1
ИЗ
РегистрСведений.Расш1_РегистрСведений1
ГДЕ
Измерение10 МЕЖДУ &Ч1 И &Ч2
И Измерение10K МЕЖДУ &Ч3 И &Ч4
Сначала прогоним запросы с выборками на точное совпадение, т.е. результат должен иметь минимальное число строк. Результаты запроса к первому регистру с планом выполнения запроса:
ВЫБРАТЬ
Измерение10,
Измерение10K,
Ресурс1
ИЗ
РегистрСведений.Расш1_РегистрСведений1
ГДЕ
Измерение10 = 2
И Измерение10K = 2000
06:56.352000-4996,DBPOSTGRS,6,Sql='SELECT
T1._Fld53929,
T1._Fld53930,
T1._Fld53931
FROM _InfoRg53928X1 T1
WHERE (T1._Fld53929 = CAST(2 AS NUMERIC)) AND (T1._Fld53930 = CAST(2000 AS NUMERIC))'
Bitmap Heap Scan on public._inforg53928x1 t1 (cost=4.24..43.19 rows=10 width=12) (actual time=0.182..0.269 rows=9 loops=1)
Output: _fld53929, _fld53930, _fld53931
Recheck Cond: ((t1._fld53929 = '2'::numeric) AND (t1._fld53930 = '2000'::numeric))
Heap Blocks: exact=9
Buffers: shared hit=12
-> Bitmap Index Scan on _inforg53928_2x1 (cost=0.00..4.24 rows=10 width=0) (actual time=0.136..0.137 rows=9 loops=1)
Index Cond: ((t1._fld53929 = '2'::numeric) AND (t1._fld53930 = '2000'::numeric))
Buffers: shared hit=3
Planning Time: 0.595 ms
Execution Time: 0.359 ms
Результаты второго регистра:
ВЫБРАТЬ
Измерение10,
Измерение10K,
Ресурс1
ИЗ
РегистрСведений.Расш1_РегистрСведений2
ГДЕ
Измерение10 = 2
И Измерение10K = 2000
15:18.372000-3998,DBPOSTGRS,6,Sql='SELECT
T1._Fld53939,
T1._Fld53938,
T1._Fld53940
FROM _InfoRg53937X1 T1
WHERE (T1._Fld53939 = CAST(2 AS NUMERIC)) AND (T1._Fld53938 = CAST(2000 AS NUMERIC))'
Bitmap Heap Scan on public._inforg53937x1 t1 (cost=4.24..43.19 rows=10 width=12) (actual time=0.105..0.141 rows=5 loops=1)
Output: _fld53939, _fld53938, _fld53940
Recheck Cond: ((t1._fld53938 = '2000'::numeric) AND (t1._fld53939 = '2'::numeric))
Heap Blocks: exact=5
Buffers: shared hit=8
-> Bitmap Index Scan on _inforg53937_2x1 (cost=0.00..4.24 rows=10 width=0) (actual time=0.075..0.076 rows=5 loops=1)
Index Cond: ((t1._fld53938 = '2000'::numeric) AND (t1._fld53939 = '2'::numeric))
Buffers: shared hit=3
Planning Time: 0.440 ms
Execution Time: 0.223 ms
Как видно, при таких запросах разницы в эффективности между регистрами нет никакой, всё на уровне погрешности измерения, планировщик СУБД PostgreSQL эффективно использует Bitmap Index Scan, запросы выполняются сильно меньше миллисекунды.
Тест составного индекса, широкая выборка по низкоселективному измерению
Модифицируем запрос, чтобы он выдал больше строк, увеличив выборку по Измерению10. Результаты первого регистра:
ВЫБРАТЬ
Измерение10,
Измерение10K,
Ресурс1
ИЗ
РегистрСведений.Расш1_РегистрСведений1
ГДЕ
Измерение10 МЕЖДУ 0 и 5
И Измерение10K = 2000
44:58.291000-670998,DBPOSTGRS,6,Sql='SELECT
T1._Fld53929,
T1._Fld53930,
T1._Fld53931
FROM _InfoRg53928X1 T1
WHERE (T1._Fld53929 >= CAST(0 AS NUMERIC)) AND (T1._Fld53929 <= CAST(5 AS NUMERIC)) AND (T1._Fld53930 = CAST(2000 AS NUMERIC))'
Gather (cost=1000.00..15022.96 rows=59 width=12) (actual time=30.723..335.473 rows=48 loops=1)
Output: _fld53929, _fld53930, _fld53931
Workers Planned: 1
Workers Launched: 1
Buffers: shared hit=6370
-> Parallel Seq Scan on public._inforg53928x1 t1 (cost=0.00..14017.06 rows=35 width=12) (actual time=20.006..327.338 rows=24 loops=2)
Output: _fld53929, _fld53930, _fld53931
Filter: ((t1._fld53929 >= '0'::numeric) AND (t1._fld53929 <= '5'::numeric) AND (t1._fld53930 = '2000'::numeric))
Rows Removed by Filter: 499976
Buffers: shared hit=6370
Worker 0: actual time=9.656..322.514 rows=23 loops=1
Buffers: shared hit=3137
Planning Time: 0.255 ms
Execution Time: 335.525 ms
Теперь всё плохо: составной индекс проигнорирован, планировщик применил скан таблицы, выполнение заняло 335 миллисекунд! Планировщик при этом посчитал возможным распараллелить выполнение. Результаты по второму регистру:
ВЫБРАТЬ
Измерение10,
Измерение10K,
Ресурс1
ИЗ
РегистрСведений.Расш1_РегистрСведений2
ГДЕ
Измерение10 МЕЖДУ 0 и 5
И Измерение10K = 2000
51:47.518000-2999,DBPOSTGRS,6,Sql='SELECT
T1._Fld53939,
T1._Fld53938,
T1._Fld53940
FROM _InfoRg53937X1 T1
WHERE (T1._Fld53939 >= CAST(0 AS NUMERIC)) AND (T1._Fld53939 <= CAST(5 AS NUMERIC)) AND (T1._Fld53938 = CAST(2000 AS NUMERIC))'
Bitmap Heap Scan on public._inforg53937x1 t1 (cost=4.65..224.56 rows=59 width=12) (actual time=0.112..0.387 rows=66 loops=1)
Output: _fld53939, _fld53938, _fld53940
Recheck Cond: ((t1._fld53938 = '2000'::numeric) AND (t1._fld53939 >= '0'::numeric) AND (t1._fld53939 <= '5'::numeric))
Heap Blocks: exact=66
Buffers: shared hit=69
-> Bitmap Index Scan on _inforg53937_2x1 (cost=0.00..4.64 rows=59 width=0) (actual time=0.078..0.078 rows=66 loops=1)
Index Cond: ((t1._fld53938 = '2000'::numeric) AND (t1._fld53939 >= '0'::numeric) AND (t1._fld53939 <= '5'::numeric))
Buffers: shared hit=3
Planning Time: 0.250 ms
Execution Time: 0.453 ms
Результат замечательный, наш составной индекс в деле и запрос выполняется меньше миллисекунды.
Тест составного индекса, широкая выборка по высоселективному измерению
Результаты по первому регистру:
ВЫБРАТЬ
Измерение10,
Измерение10K,
Ресурс1
ИЗ
РегистрСведений.Расш1_РегистрСведений1
ГДЕ
Измерение10 = 2
И Измерение10K МЕЖДУ 0 И 5000
02:25.414000-299998,DBPOSTGRS,6,Sql='SELECT
T1._Fld53929,
T1._Fld53930,
T1._Fld53931
FROM _InfoRg53928X1 T1
WHERE (T1._Fld53929 = CAST(2 AS NUMERIC)) AND (T1._Fld53930 >= CAST(0 AS NUMERIC)) AND (T1._Fld53930 <= CAST(5000 AS NUMERIC))'
Bitmap Heap Scan on public._inforg53928x1 t1 (cost=1667.92..8843.34 rows=50339 width=12) (actual time=80.936..130.690 rows=50359 loops=1)
Output: _fld53929, _fld53930, _fld53931
Recheck Cond: ((t1._fld53929 = '2'::numeric) AND (t1._fld53930 >= '0'::numeric) AND (t1._fld53930 <= '5000'::numeric))
Heap Blocks: exact=6368
Buffers: shared hit=6719
-> Bitmap Index Scan on _inforg53928_2x1 (cost=0.00..1662.88 rows=50339 width=0) (actual time=76.523..76.523 rows=50359 loops=1)
Index Cond: ((t1._fld53929 = '2'::numeric) AND (t1._fld53930 >= '0'::numeric) AND (t1._fld53930 <= '5000'::numeric))
Buffers: shared hit=351
Planning Time: 0.774 ms
Execution Time: 137.417 ms
Планировщик индекс использует. Результаты по второму регистру:
ВЫБРАТЬ
Измерение10,
Измерение10K,
Ресурс1
ИЗ
РегистрСведений.Расш1_РегистрСведений2
ГДЕ
Измерение10 = 2
И Измерение10K МЕЖДУ 0 И 5000
53:19.296000-1420998,DBPOSTGRS,6,Sql='SELECT
T1._Fld53939,
T1._Fld53938,
T1._Fld53940
FROM _InfoRg53937X1 T1
WHERE (T1._Fld53939 = CAST(2 AS NUMERIC)) AND (T1._Fld53938 >= CAST(0 AS NUMERIC)) AND (T1._Fld53938 <= CAST(5000 AS NUMERIC))'
Seq Scan on public._inforg53937x1 t1 (cost=0.00..19370.00 rows=50448 width=12) (actual time=0.038..687.889 rows=50125 loops=1)
Output: _fld53939, _fld53938, _fld53940
Filter: ((t1._fld53938 >= '0'::numeric) AND (t1._fld53938 <= '5000'::numeric) AND (t1._fld53939 = '2'::numeric))
Rows Removed by Filter: 949875
Buffers: shared hit=6370
Planning:
Buffers: shared hit=4
Planning Time: 0.713 ms
Execution Time: 695.252 ms
Составной индекс не используется, вместо него планировщик PostgreSQL выбрал сканирование таблицы в миллион строк, распараллелить выполнение даже не подумал.
Итоги
| Запрос | Регистр 1 (высокоселективный индекс в конец) | Регистр 2 (высокоселективный индекс в начале) |
|---|---|---|
| Узкая выборка по двум измерениям | Index Scan (хорошо) | Index Scan (хорошо) |
| Широкая выборка по низкоселективному измерению | Seq Scan (плохо) | Index Scan (хорошо) |
| Широкая выборка по высокоселективному измерению | Index Scan (хорошо) | Seq Scan (плохо) |

Вывод: первым полем в составном индексе должно быть то поле, по которому предполагается делать наиболее узкие выборки. При этом неважно, какая у него селективность. Поля, по которым делаются широкие выборки - помещать в конец. При оценке "широкости" выборки следует смотреть не только на условие ГДЕ в тексте запроса, но и смотреть на тип этого поля и знать распределение значений в данных. Допустим, у нас измерение типа Булево и миллион строк в таблице. Если значения в строках данных Истина и Ложь в этом поле по количеству сравнимы, то любое условие в запросе по этому полю будет давать широкую выборку - значит помещаем измерение в конец. Если же все строки имеют значение Ложь, кроме десятка со значением Истина, а поставленная задача требует делать выборку только ГДЕ ИзмерениеХ = ИСТИНА, то запрос будет давать узкую выборку - тогда такое измерение типа Булево нужно размещать в начале или ближе к началу.
Приложение: файл настройки ТЖ для снятия планов выполнения запросов (поменять имя таблицы на своё):
<?xml version="1.0" encoding="UTF-8"?>
<config xmlns="http://v8.1c.ru/v8/tech-log">
<dump create="false"/>
<log location="/var/log/1C" history="24">
<event>
<eq property="name" value="DBPOSTGRS"/>
<like property="sql" value="%InfoRg53937X1%"/>
</event>
<property name="durationus"/>
<property name="sql"/>
<property name="plansqltext"/>
</log>
<plansql/>
</config>