

Интеграция платформы 1С с хранилищем S3. Разбор механизма

Введение
Почитать что такое S3 можно, например, здесь: S3. Понятно, что с хранилищами S3 из 1С можно было работать и раньше, через протокол http с помощью HTTPСоединение. В данной статье будет разбор как работает новый механизм интеграции с S3 на уровне платформы, когда программисту вообще ничего специально писать не нужно, а платформа сама размещает большие данные в хранилище S3 и извлекает их оттуда обратно.
Реквизиты
Для экспериментов нам понадобятся:
- Cвободный компьютер, подойдёт практически любой современный не маргинальный Linux с графическим окружением
- Поднять пустую информационную базу 1С в клиент-серверном режиме (8.3.27.1719): Cервер 1С Клиент 1С Клиент 1С (др.способ) Postgres PostgresPro (др. способ) Лицензия разработчика 1С
- Установите консоль администрирования DBeaver (предполагается что вы умеете им пользоваться), например из flathub:
flatpak install app/io.dbeaver.DBeaverCommunity/x86_64/stable - Поднять хранилище S3: с помощью контейнеризации podman или docker запускаем простейшее хранилище,
идеально подходящее для разработчиков и экспериментов:
При выполнении команды будет показана информация, по каким адресам доступны сервисы S3.podman run --name s3 -p 9000:9000 -p 9001:9001 \ -e "MINIO_ROOT_USER=minioadmin" \ -e "MINIO_ROOT_PASSWORD=miniopassword" \ quay.io/minio/minio server /data --console-address ":9001"
В конфигурации информационной базы создайте любой объект, содержащий реквизит типа ХранилищеЗначения, в который и нужно будет записывать двоичные данные и которые являются целевым предметом для хранения в S3. Например такой регистр сведений:
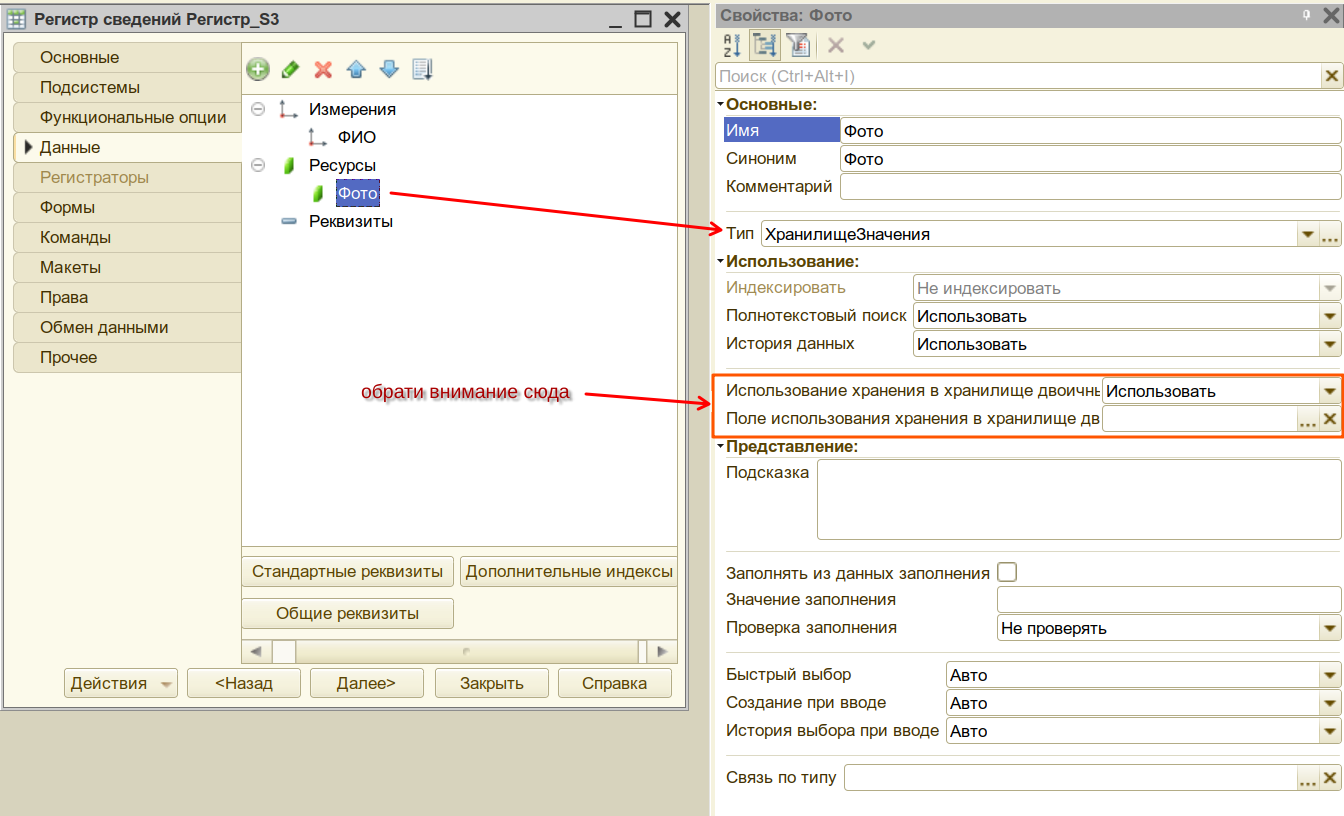
Прямоугольником выделены важные свойства, которые напрямую влияют на результаты опытов с хранилищем S3. Это значения по умолчанию. При желании, можно ещё создать у регистра реквизит булевого типа и указать его в нижнем поле, для более гибкого управления записью, но нам это усложенение не нужно и оставляем как есть.
Далее, самостоятельно напишите любой код, заполняющий и читающий данные из ресурса типа ХранилищеЗначения, данная статья и без того перегружена деталями.
Конфигурация без хранилища
Чтобы сравнить что было и что стало, давайте пока вообще не будем трогать настройки хранилища и запишем в регистр несколько записей с двоичными значениями (в моём случае это фотографии) и посмотрим с помощью DBeaver как оно легло в СУБД. Т.к. конфигурация изначально была пустая, то таблица с регистром легко находится, у меня это _inforg53. Проверим стратегию хранения блобов:
SELECT attname, attstorage FROM pg_attribute
WHERE attrelid = '_inforg53'::regclass AND attname = '_fld55';
attname|attstorage|
-------+----------+
_fld55 |x |
Этот результат означает, что применяется оптимальная стратегия EXTENDED для хранения поля _fld55 (Фото) типа bytea: если размер бинарных данных превышает 2048 байт, то данные записываются в отдельную таблицу TOAST. Подробнее об этом можно почитать здесь: TOAST. Между прочим, это опровергает популярное мнение в среде 1С-ников о том, что хранение двоичных данных в таблицах замедляет выполнение запросов: на самом деле блобы лежат в отдельной физической таблице, и они естественно во время выполнения запроса к обычным данным не считываются с диска и не могут ухудшать план его выполнения.
Смотрим, что же в таблице регистра:
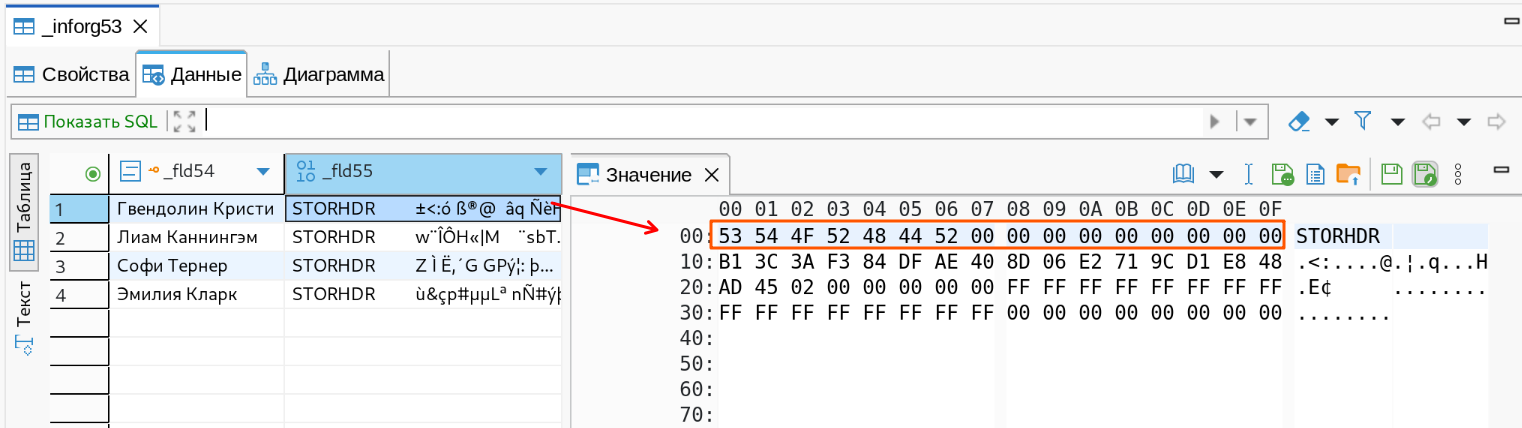
В бинарное поле записались не все загруженные данные, а всего 64 байта. Первые 16 байт это явно заголовок, указывающий что данные записаны в некое хранилище. Поищем, где же оно это хранилище? По размеру данных легко находим таблицу, это binarydata. Можно сперва подумать что это и есть внутреннее хранилище, которое используется по умолчанию когда даже не введены настройки для хранения двоичных данных, но на самом деле нет. На всякий случай испробуем запрос выше и убеждаемся что для этой таблицы тоже применяется стратегия EXTENDED для хранения в отдельной таблице TOAST.
Может быть так сработало из-за того, что мы в конфигураторе указали "Использовать" в опции "Использование хранения в хранилище двоичных данные"? Если переключить на "Не использовать" и перезагрузить в регистр файлы, то убеждаемся, что ничего не поменялось.
Зато в момент записи основной таблицы с данными начинает распухать таблица binarydata, в ней явно остаются старые данные вместе с новыми загруженными! С настройками новой платформы по умолчанию как-то уже нехорошо становится.
Похоже так происходит потому, что технология ещё сырая и текущая версия платформы (8.3.27.1719) на момент написания статьи имеет баг.
Настройка на внутреннее хранилище
Хранилище двоичных данных можно настроить как в конфигураторе (Администрирование - Управление хранилищами двоичных данных) так и в тонком клиенте. Больше функций в стандартной обработке тонкого клиента:
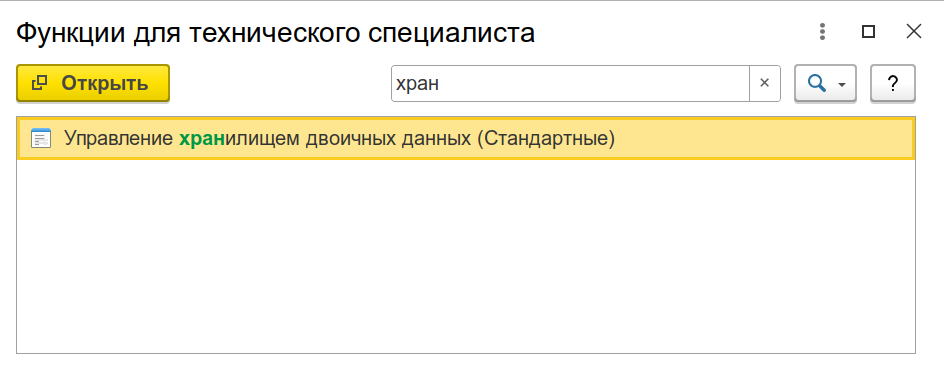
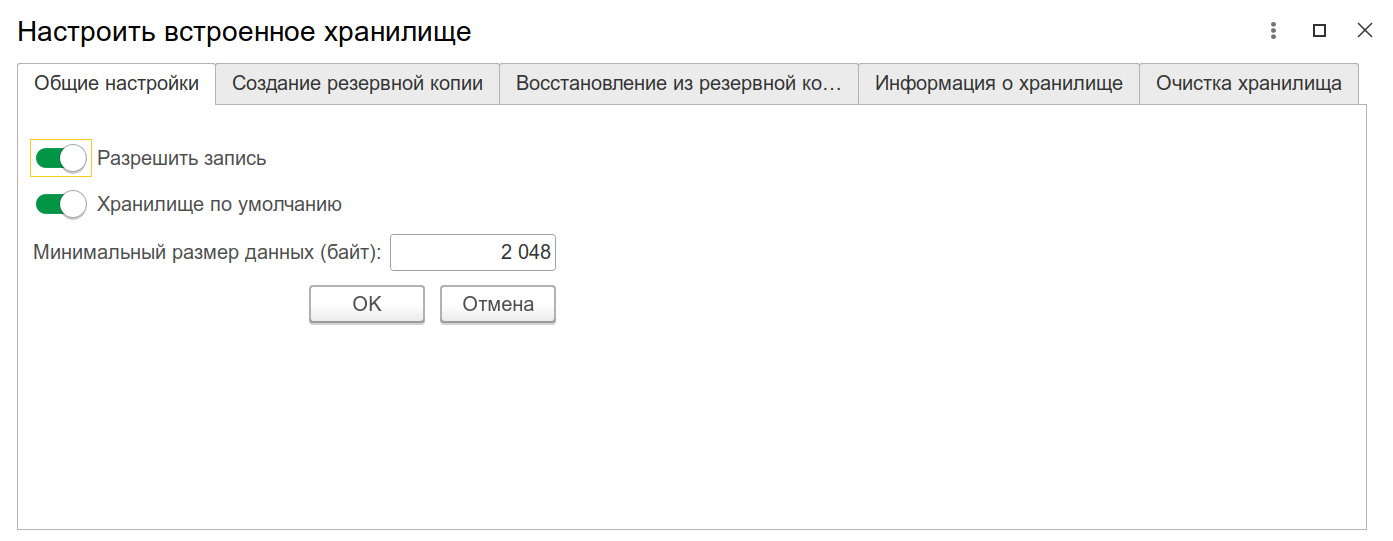
И обратите внимание на интересную кнопку, с помощью которой можно отключить от механизма отдельные реквизиты:
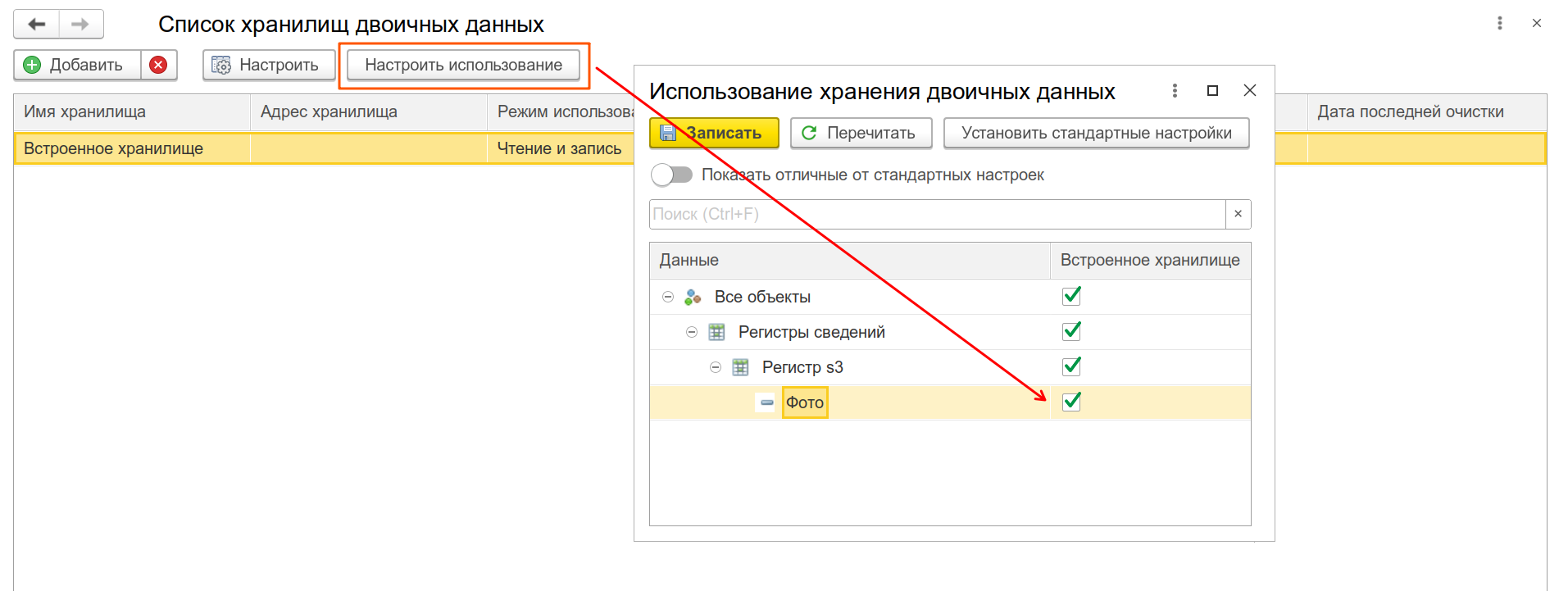
Перезагрузим файлы в регистр. Смотрим, что поменялось: в таблице _inforg53 поменялись только ссылки в бинарном поле, но таблица binarydata не очистилась. (UPDATE: В прошлой редакции этой статьи было написано что binarydata очистилась. К сожалению это оказалось не так). Новые версии файлов записались в файловую систему на сервере приложений. На досуге поищите там каталог BinDataStrg в каталоге /home/usr1cv8.
В чём получается выгода? В том, что программисту вообще больше не нужно заморачиваться и можно пихать реквизиты типа ХранилищеЗначения вообще куда удобно - платформа сама определится и запишет его не в СУБД, а в файловую систему (согласно настройкам конечно) и так же без мороки прочитает его обратно.
Проведём опыт: удалим настройку хранения в хранилище бинарных настроек, чтобы стало как в начале. Интересно, файлы переедут обратно в СУБД или просто обнулятся?
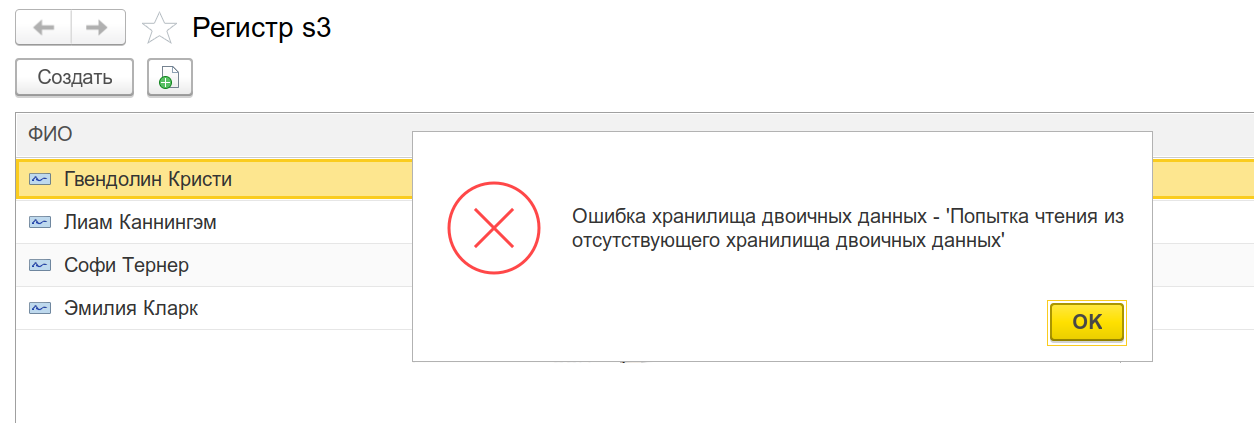

В общем, не угадал: ни то, ни другое, получили битые ссылки. Пока никто не увидел, вернём настройку на место... Уф, пронесло, картинки снова доступны и на месте )
Настройка базы на хранилище S3
Для начала, залезем через браузер в консоль управления MinIO S3 (адрес он написал куда, имя и пароль вы указали при запуске контейнера) и c помощью кнопки Create Bucket добавим бакет с именем test:
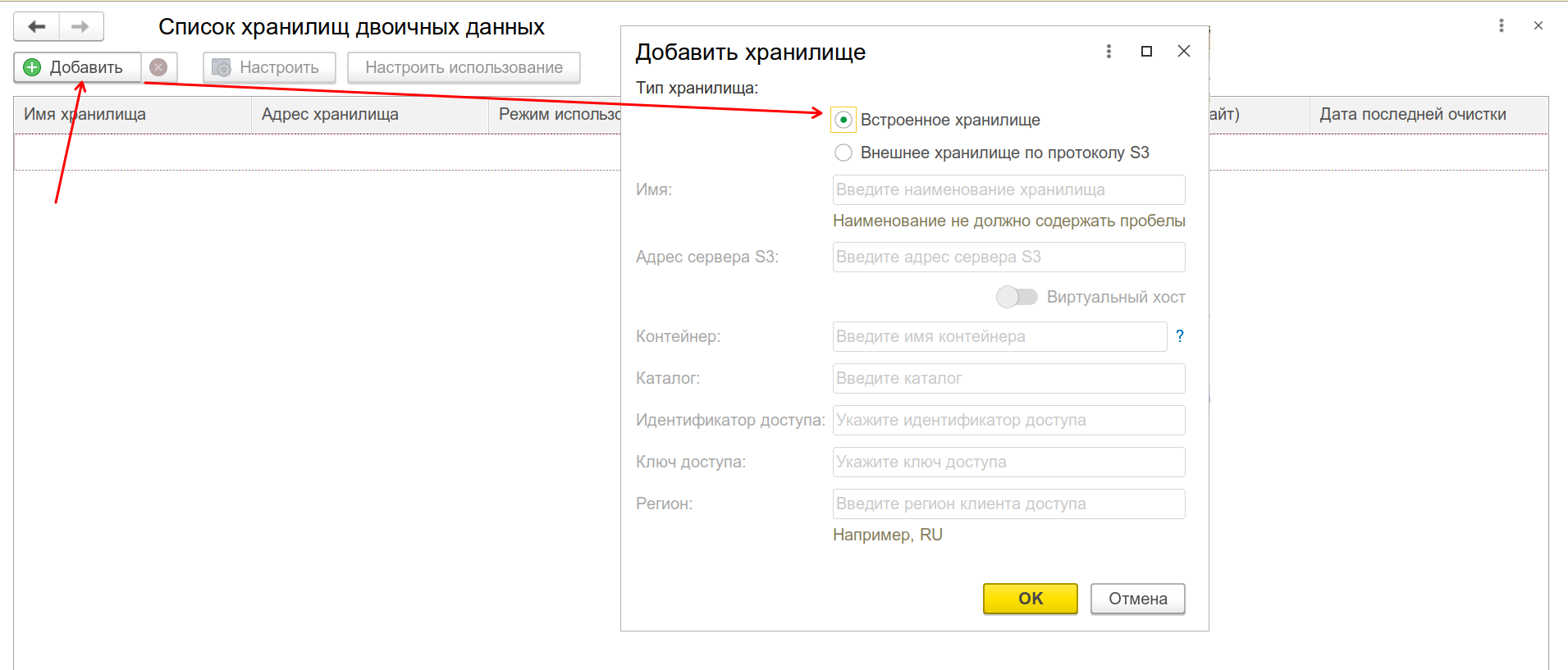
Добавим новое хранилище:
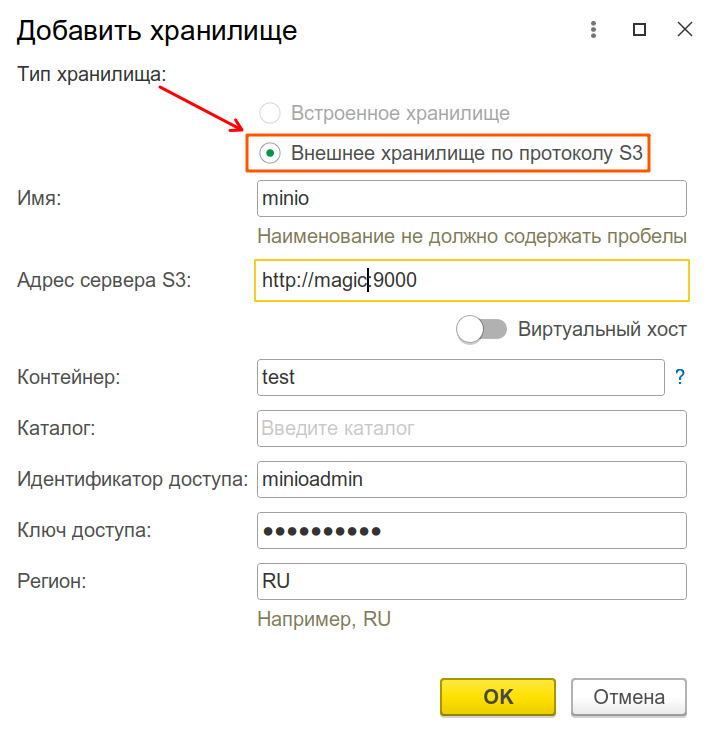
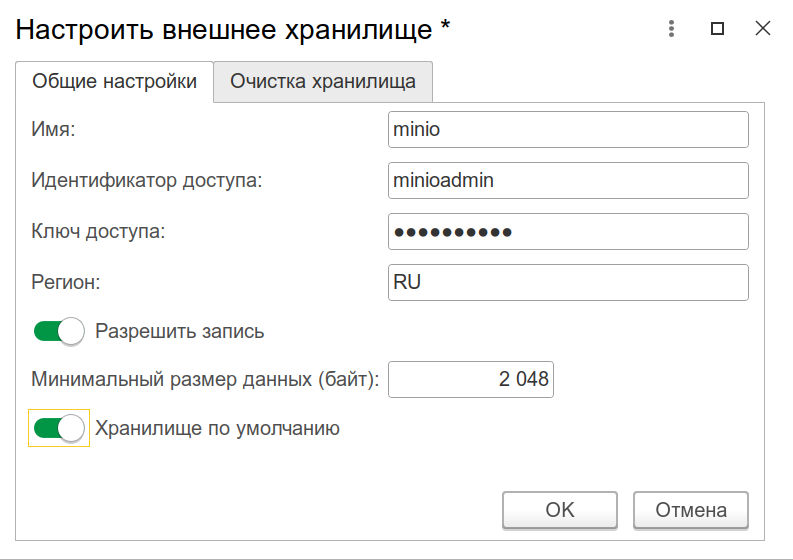
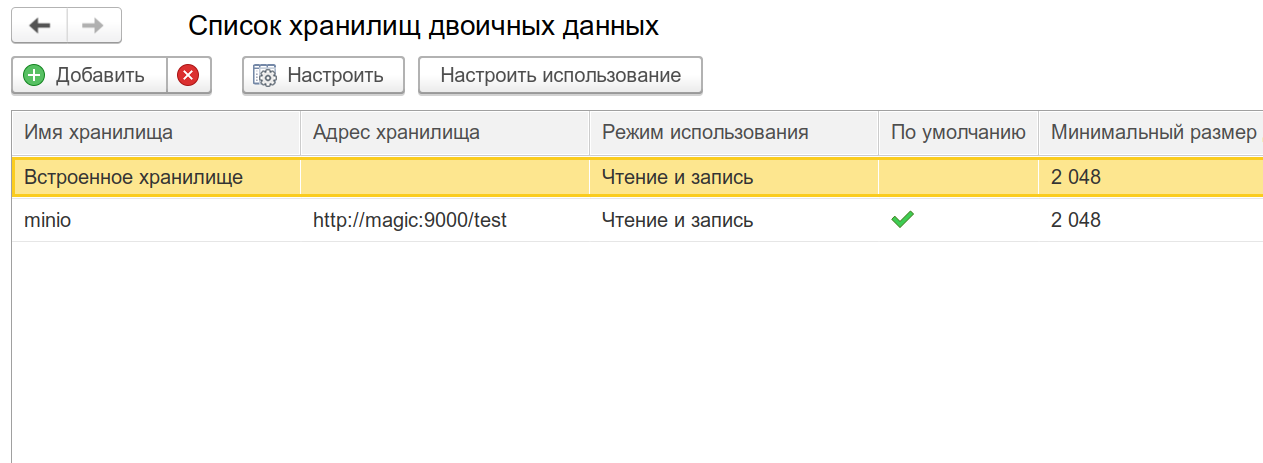
В этой настройке вам может показаться, что можно записывать параллельно сразу в 2-3 хранилища:
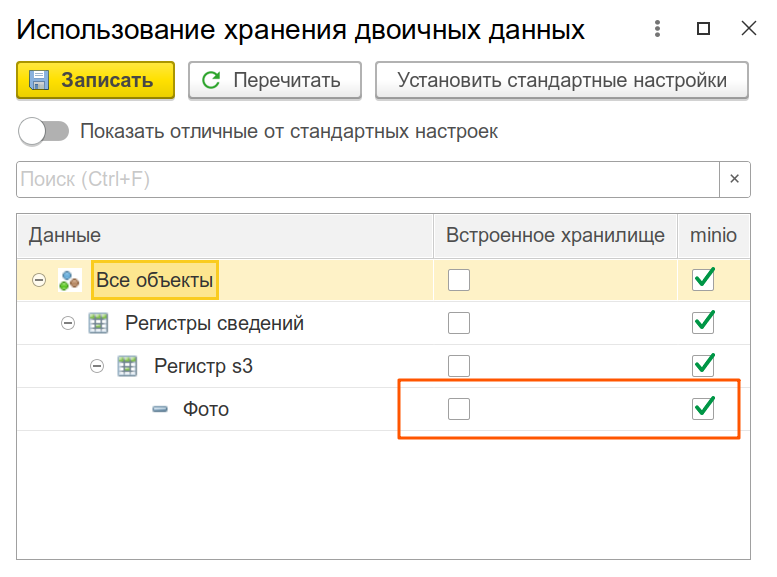
К сожалению, только показалось - "в трёх экземплярах" записывать нельзя.
Все старые фотки на месте. Перезальём одну фотку и посмотрим что произошло. Во-первых, в хранилище MinIO сразу прилетел блоб со значением типа ХранилищеЗначения:
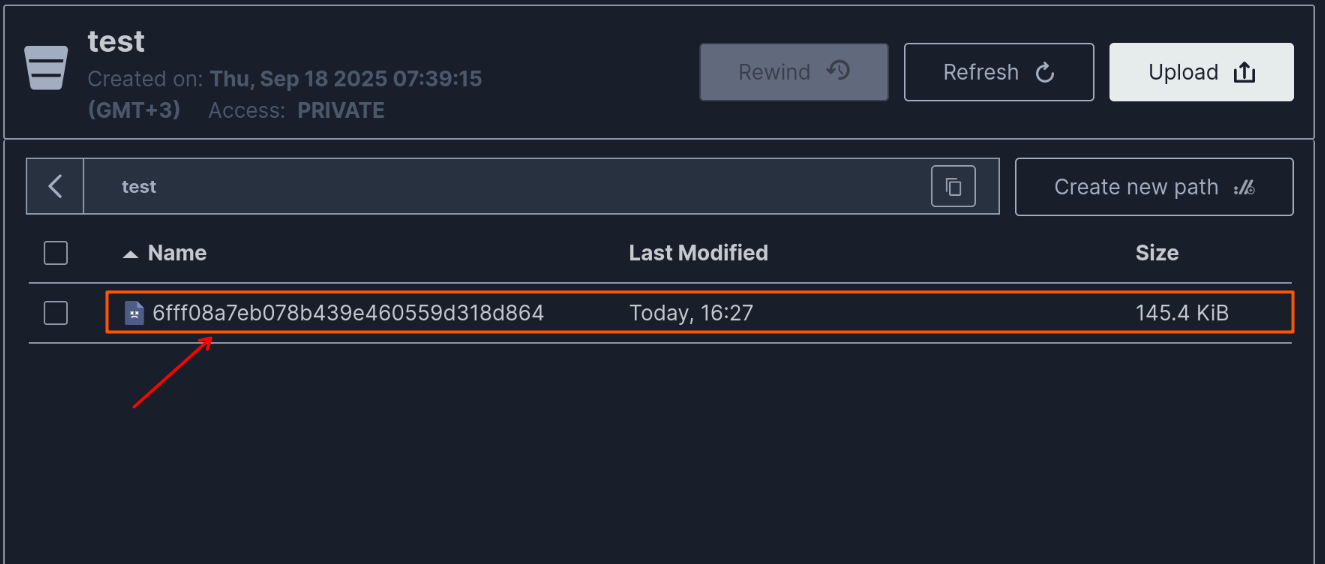
В таблице binarydata ничего не происходит, зато в binarydatastoragecontent появились интересные строки:
select f_type, f_str1, f_num5, f_vstr1, f_vstr2, f_vstr3, f_vstr4 from binarydatastoragecontent;;
f_type |f_str1 |f_num5|f_vstr1 |f_vstr2 |f_vstr3 |f_vstr4|
----------------+--------------------+------+----------------------+----------+-------------+-------+
STORE | | 2048| | | | |
STORE |minio | 2048|http://magic:9000/test|minioadmin|miniopassword|RU |
DEFAULT | | 0| | | | |
Здесь и хранятся все настройки двоичных хранилищ, включая S3. Обратите внимание, имя и пароль для доступа к хранилищу S3 лежат в незашифрованном виде! Если у вас "кровавый энтерпрайз" и ваши безопасники хоть немного образованные люди и прочтут эти строки, то дальше вопрос целесообразности применения интеграции с S3 скорее всего на этом будет закрыт, особенно если вы собирались там хранить конфиденциальные файлы. Сорян друзья, спалил малину.
Думаю 1С наверняка в будущих версиях платформы переместит место хранения пароля S3 в защищённоё хранилище
Проведём снова опыт: удалим настройку хранилища S3 и снова его восстановим. Те данные, что лежали во внутреннем хранилище, никуда не делись и нормально открываются. Зато с данными на S3 беда:
ОБРАТИТЕ ВНИМАНИЕ: после восстановления настройки ошибка не исчезает, связи с хранилищем S3 потеряны навсегда!

Причина - в битой ссылке. В таблице binarydatastoragecontent при создании настройки S3 в поле f_key прописывается новый id хранилища. Именно это значение прописано в поле данных:
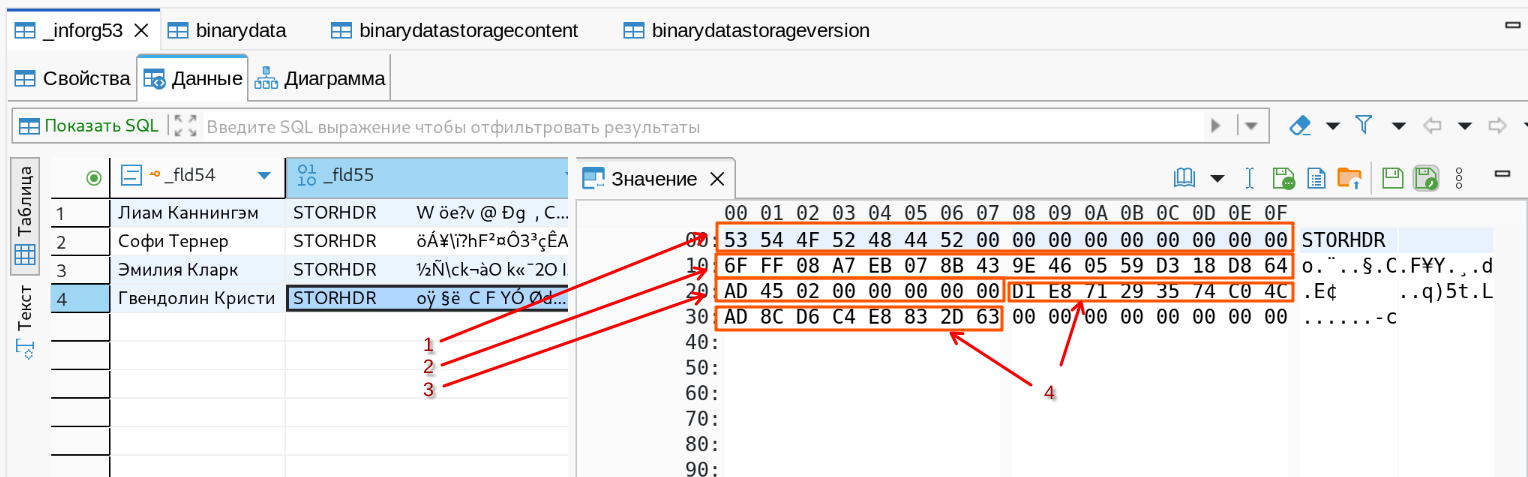
- 1 - стандартный заголовок (16 байт)
- 2 - ключ хранения данных в S3 (16 байт), вернитесь посмотреть картинку выше и убедитесь что в бакете те же значения в виде строки.
- 3 - размер блоба в байтах, int64_t (8 байт)
- 4 - идентификатор хранилища (16 байт) = поле f_key в таблице binarydatastoragecontent
Таким образом, для восстановления битых ссылок после досадного конфуза с настройками нужно подменить 16 байт (блок 4) на новый идентификатор хранилища, т.е требуется прямое вмешательство в данные СУБД. Либо наоборот - поменять идентификатор настроек поле f_key в таблице binarydatastoragecontent на старое значение. Второе конечно будет быстрее. Я проверил ручным редактированием hex-кода в DBeaver - метод рабочий.
Было бы прекрасно, если бы 1С добавил в будущих релизах возможность указания идентификатора в стандартной настройке хранилища S3
Ещё один важный опыт: что будет, если сервис S3 упал? Роняем сервис и смотрим: при попытке чтения из S3 выходит несколько иная ошибка:
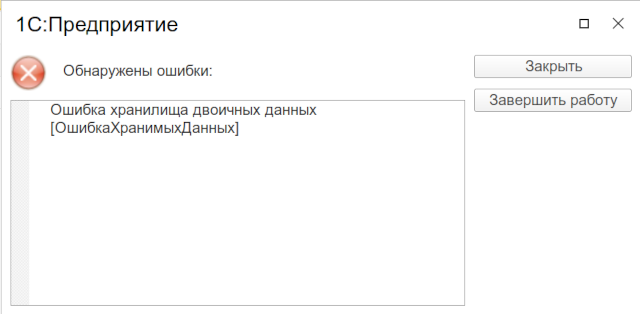
При попытке записи накакой ошибки не выбрасывается! Но фактически запись не осуществляется и при чтении снова выходит ошибка. Если же снова запустить S3, то ошибка не исчезает и от него довольно трудно избавиться, т.к. удалить проблемную запись из 1С вы тоже не сможете. Поможет только прямое вмешательство в запись на СУБД!
Спишем это на сырость реализации технологии, так быть не должно! Ждём исправления в будущих релизах платформы.
Есть ещё одна потенциальная проблема, которая не сразу очевидна: допустим, у вас несколько информационных баз и вы даже сумели настроить хранение на S3 с одинаковым идентификатором настройки - но всё равно не получится просто так передавать внутреннюю 64-байтную ссылку ХранилищаЗначения между двумя и более информационными базами, без вмешательства в таблицы СУБД прямыми запросами. Получается, что эффективную общую базу двоичных данных на этом построить нельзя.
Было бы неплохо, если в будущих релизах платформы 1С появилась возможность сериализовать ссылки на данные, хранимые в S3.
Выгрузка в DT
Тут всё ожидаемо - данные из хранилищ перекочевали в таблицу binarydata. Таким образом выгрузка DT будет включать в себя терабайты данных из хранилища, если они у вас будут.
Заключение
1) Сложно что-либо посоветовать. Реализация интеграции с S3 на данный момент явно сырая, при этом я даже не испытывал сервис нагрузочными тестами, а уже использовать такое стало страшно. Если у вас существует информационная безопасность, то и думать не придётся (см. предупреждение про пароли в таблице настроек).
2) Использовать встроенное хранилище - думаю можно. В свете проблемы неадекватного роста таблицы binarydata даже нужно.
3) Ввиду изменения механизма хранения и сваливания в одну таблицу binarydata всех реквизитов типа ХранилищеЗначения теряет всякий смысл паттерн разработки (БСП), когда к каждому объекту создается парный с суффиксом ПрисоединенныеФайлы. Теперь, вне зависимости от настроек хранения, можно не париться насчёт эффективности и спокойно добавлять реквизиты типа ХранилищеЗначения к любым объектам.