

Многопоточная непрерывная обработка данных на платформе 1С с помощью Mutex

Концепция
Разработчики многопоточных алгоритмов на некоторых низкоуровневых языках программирования не могут пройти мимо близкого знакомства с такими сущностями, как Mutex (Мьютекс) или Spinlock (Спинлок).
В языке 1С такая концепция отсутствует, ввиду невозможности прямого доступа к данным модуля другого потока: всё "общение" с потоком происходит через передачу ему параметров (через значение!) и ожидания возврата результата во временном хранилище. Таким образом, в 1С для выполнения тяжелой задачи требуется разбить его на порции и для каждой порции запускать обработку в отдельном потоке, затем ожидать окончания этих потоков и собрать результаты из временных хранилищ в какой-то один общий результат. Получается, что используя возможности языка 1С можно реализовать только что-то похожее на кооперативную многозадачность.
Типичный 1С-алгоритм разбивает весь объем данных на число разрешенных ядер, и запускает такое же количество потоков. Основной недостаток такого подхода - плохая балансировка нагрузки на ядра, т.к. если какая-то порция обработается быстро и поток завершится, то освободившееся ядро нельзя загрузить оставшимися данными, так как всё уже заранее распределено на другие потоки. Второй встречающийся вариант - поделить на мелкие порции и для каждой мелкой порции запускать свой поток до завершения. Однако запуск потока и его завершение - это сравнительно ресурсоёмкая операция.
В связи с вышеозначенными проблемами тема мьютекса для конкурентного доступа к разделяемым данным периодичеки возникает на просторах Интернета среди наиболее продвинутых сообществ 1С, но дальше разговоров до каких-либо функционирующих реализаций дело не доходит, по крайней мере я их не встречал в свободном доступе. Так давайте раскроем вопрос до конца! Для начала взглянем на пример работы mutex с использованием библиотеки pthread на языке C:
#include <pthread.h>
pthread_mutex_t mutex;
uint32_t someVar;
void startInThreads( ... ) {
// инициализация мьютекса:
pthread_mutex_init(&mutex, NULL);
// { здесь запуск потоков и ожидание их завершения }
// уничтожение мьютекса:
pthread_mutex_destroy(&mutex);
}
// код потока
void* runThread(void* ptr) {
while(true) {
// { здесь может быть код с длительными вычислениями }
// Накладываем блокировку:
pthread_mutex_lock(&mutex);
// Этот кусок кода выполняется в каждый отрезок времени только в
// одном потоке, другие конкурирующие потоки ждут освобождения мьютекса.
// Можно безопасно читать и записывать в глобальные переменные (разделяемые данные между потоками):
someVar = someFunc();
// освобождаем блокировку для других потоков:
pthread_mutex_unlock(&mutex);
// { здесь может быть код с длительными вычислениями }
}
}
Как видно в пояснении, существует участок кода, который может выполняться эксклюзивно только в одном из потоков на отрезке времени, а остальные достигнув этот участок кода будут ожидать освобождения мьютекса. Таким образом разрешается конфликт одновременного доступа к разделяемым данным из нескольких потоков. Эксперты 1С сразу же вспомнят, что это похоже на поведения транзакций СУБД с уровенем изоляции Serializable. Ну что ж, угадали, именно этот механизм я и буду использовать для реализации Mutex на 1С.
Реализация mutex средствами платформы 1С
Итак, попытаемся слепить подобие мьютекса из тех возможностей, которые предоставляет платформа 1С. В качестве основы нашего нового класса (в терминах ООП) будем использовать независимый непериодический регистр сведений. Создаём новый РС и добавляем одно измерение типа Число (длина 1, точность 0, неотрицательное) и один ресурс типа ХранилищеЗначения:
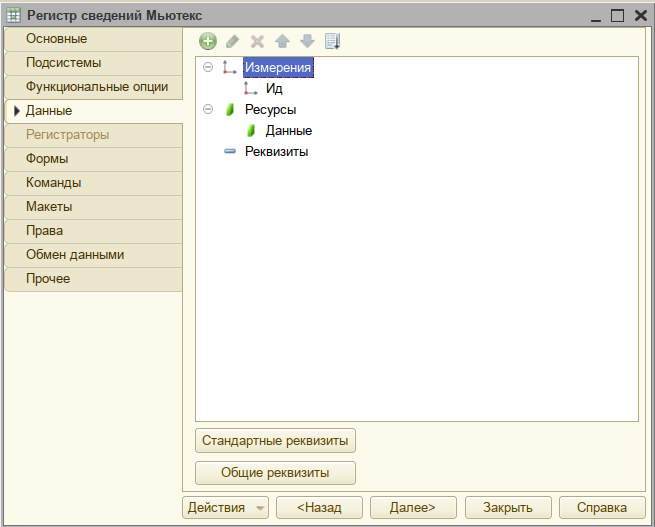
В модуле менеджера создадим три аналога public static методов:
Процедура СоздатьЭкземпляр(Ид, Данные = Неопределено) Экспорт
МенеджерЗаписи = РегистрыСведений.Мьютекс.СоздатьМенеджерЗаписи();
МенеджерЗаписи.Ид = Ид;
МенеджерЗаписи.Данные = Новый ХранилищеЗначения(Данные);
МенеджерЗаписи.Записать();
КонецПроцедуры
Функция ПолучитьЭкземпляр(Ид) Экспорт
НаборЗаписей = РегистрыСведений.Мьютекс.СоздатьНаборЗаписей();
НаборЗаписей.Ид = Ид;
Возврат НаборЗаписей;
КонецФункции
Процедура УдалитьЭкземпляр(Ид) Экспорт
МенеджерЗаписи = РегистрыСведений.Мьютекс.СоздатьМенеджерЗаписи();
МенеджерЗаписи.Ид = Ид;
МенеджерЗаписи.Прочитать();
МенеджерЗаписи.Удалить();
КонецПроцедуры
В модуле набора записей описываем public переменную, главный public метод и один private метод:
Перем Ид Экспорт;
Процедура ОбработатьДанныеЭксклюзивно(Действие = "", ДанныеПотока = Неопределено) Экспорт
НачатьТранзакцию();
Блокировка = Новый БлокировкаДанных;
ЭлементБлокировки = Блокировка.Добавить();
ЭлементБлокировки.Область = "РегистрСведений.Мьютекс";
ЭлементБлокировки.Режим = РежимБлокировкиДанных.Исключительный;
ЭлементБлокировки.УстановитьЗначение("Ид", Ид);
// установка блокировки
Блокировка.Заблокировать();
Прочитать();
Данные = ЭтотОбъект[0].Данные.Получить();
ПроизвестиОбменДанными(Действие, ДанныеПотока, Данные);
ЭтотОбъект[0].Данные = Новый ХранилищеЗначения(Данные);
Записать();
ЗафиксироватьТранзакцию();
КонецПроцедуры
// Процедура - Произвести обмен данными между ДаннымиПотока и общими Данными
//
// Параметры:
// ДанныеПотока - Произвольный - Данные, полученные из потока
// Данные - Произвольный - Общие данные для храненения параметров и результата
//
Процедура ПроизвестиОбменДанными(Действие, ДанныеПотока, Данные)
// пишем код обмена здесь
КонецПроцедуры
Схема работы нашего планировщика проста: весь объем обрабатываемых данных делим на небольшие порции, количество этих порций гораздо больше числа потоков. Далее запускаем требуемое число потоков и эти потоки начинают обрабатывать параллельно порции данных, периодически считывая новые задания и сбрасывая результат в Данные (список заданий), при этом потоки не завершаются и работают до тех пор, пока не закончатся задания (необработанные порции данных).
Любой учебник по проектированию многопоточных систем вам расскажет, что проблема состоит в том, что мы не можем заранее предсказать длительность обработки порций данных и при прямолинейной реализации алгоритма обращение к списку заданий из потоков будет хаотичным и его содержание неконсистентым. Именно в этом месте нам и нужен мьютекс для атомарного чтения и изменения списка заданий.
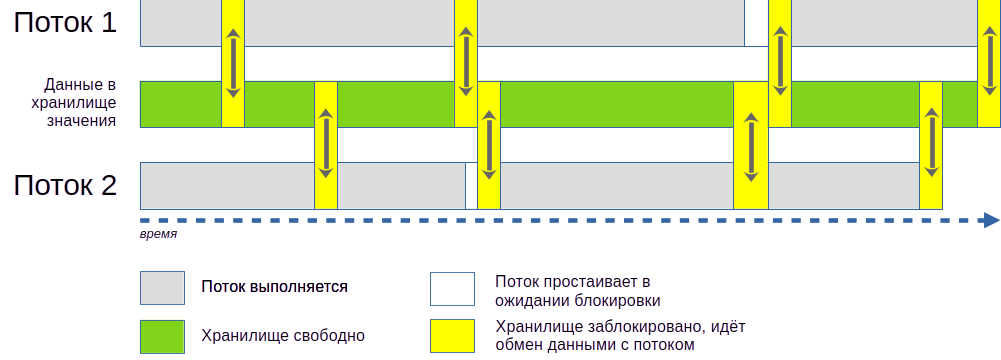
Процедура ОбработатьДанныеЭксклюзивно (на схеме это жёлтые блоки)) и является ядром механизма Mutex и предназначена для вызова из потоков. Глобальные Данные со списком заданий будут храниться в хранилище значения в регистре, а данные для записи или чтения из него мы будем передавать в параметре ДанныеПотока. Таким образом между ними можно будет осуществлять обмен в режиме онлайн прямо во время выполнения потоков! Логику обмена прописываем в процедуре ПроизвестиОбменДанными.
Пример полной реализации работы mutex на примере вычисления простых чисел
Я намеренно использую самый долгий неоптимальный алгоритм вычисления простых чисел в заданном диапазоне, чтобы одинаковые по длине порции данных обрабатывались с существенно разной скоростью и расчёты занимали больше времени.
Создаём общий серверный модуль ДлительныеРасчеты и добавляем:
Функция ПростыеЧислаВИнтервале(НачалоИнтервала, КонецИнтервала)
Результат = Новый Массив;
Для Ч = НачалоИнтервала По КонецИнтервала Цикл
ЭтоПростоеЧисло = Истина;
Для М = 2 По Ч - 1 Цикл
Если Ч % М = 0 Тогда
ЭтоПростоеЧисло = Ложь;
КонецЕсли;
КонецЦикла;
Если ЭтоПростоеЧисло Тогда
Результат.Добавить(Ч);
КонецЕсли;
КонецЦикла;
Возврат Результат;
КонецФункции
Для организации списка заданий и раздачи порций потокам понадобится таблица значений. Его и будем использовать в качестве разделяемых Данных с атомарным доступом и держать в ресурсе регистра сведений. Здесь мне пришла мысль, что эта таблица должна быть вообще универсальной для разных задач, поэтому сразу добавим в модуль менеджера Мьютекса следующую функцию, которая создает таблицу заданий и сразу заполняет его порциями:
Функция СоздатьЗаполнитьТаблицуЗаданий(Начало, Конец, ДлинаПорции) Экспорт
Результат = Новый ТаблицаЗначений;
ТипЧисло = Новый ОписаниеТипов("Число");
ТипСтрока = Новый ОписаниеТипов("Строка");
// Начало диапазона:
Результат.Колонки.Добавить("Начало", ТипЧисло);
// Конец дипазона:
Результат.Колонки.Добавить("Конец", ТипЧисло);
// Статус задания:
Результат.Колонки.Добавить("Статус", ТипСтрока);
// Результат задания (произвольный, необязательный):
Результат.Колонки.Добавить("Результат");
Н = Начало;
Пока Истина Цикл
К = Н + ДлинаПорции;
Если К > Конец Тогда
К = Конец;
КонецЕсли;
НСтр = Результат.Добавить();
НСтр.Начало = Н;
НСтр.Конец = К;
Н = К + 1;
Если Н >= Конец Тогда
Прервать;
КонецЕсли;
КонецЦикла;
Возврат Результат;
КонецФункции
В колонке Статус будем помечать, что порция захвачена потоком или была обработана. Результат обработки порции будем записывать в колонку Результат. Чаще всего в реальной жизни придется записывать результаты длительной обработки в базу данных (например переписывать регистры, создавать документы), поэтому запись в колонку Результат является факультативной. Но для нашей задачи вполне уместно записывать именно в неё.
Должен предупредить, что перезапись ТаблицыЗначений в ресурсе типа ХранилищеЗначения является возможно не самым эффективным способом раздачи порций, в иных условиях может быть выгоднее использовать строки и измерения регистра сведений, а блокировку устанавливать более избирательно, особенно если число порций исчисляется десятками и сотнями тысяч. Способ через Хранилище проще для понимания всей механики и требует меньше кода.
Код потока добавляем в общий модуль ДлительныеРасчеты:
Процедура ПростыеЧисла() Экспорт
ДанныеПотока = Новый Структура("Статус,Начало,Конец,Результат");
ДанныеПотока.Статус = "Пустой";
ДанныеПотока.Начало = 0;
ДанныеПотока.Конец = 0;
ДанныеПотока.Результат = Неопределено;
Мьютекс = РегистрыСведений.Мьютекс.ПолучитьЭкземпляр(0);
Пока Истина Цикл
// отдаем результат (если есть) и забираем новую порцию:
Мьютекс.ОбработатьДанныеЭксклюзивно("ОтдатьЗабратьПорцию", ДанныеПотока);
Если ДанныеПотока.Статус = "Пустой" Тогда
// все задания закончились, завершаем поток
Прервать;
Иначе
ДанныеПотока.Результат = ПростыеЧислаВИнтервале(ДанныеПотока.Начало, ДанныеПотока.Конец);
КонецЕсли;
КонецЦикла;
Конецпроцедуры
Для обмена данными понадобится дописать в модуле набора записей:
Процедура ПроизвестиОбменДанными(Действие, ДанныеПотока, Данные)
Если Действие = "ОтдатьЗабратьПорцию" Тогда
ОтдатьЗабратьПорцию(ДанныеПотока, Данные)
ИначеЕсли Действие = "ПрочитатьРезультат" Тогда
ПрочитатьРезультат(ДанныеПотока, Данные);
КонецЕсли;
КонецПроцедуры
Процедура ОтдатьЗабратьПорцию(ДанныеПотока, Данные)
Если ДанныеПотока.Результат <> Неопределено Тогда
П = Новый Структура;
П.Вставить("Статус", "ВыданоЗадание");
П.Вставить("Начало", ДанныеПотока.Начало);
П.Вставить("Конец", ДанныеПотока.Конец);
ДанныеСтроки = Данные.НайтиСтроки(П);
Если ДанныеСтроки.Количество() > 0 Тогда
Строка = ДанныеСтроки[0];
ЗаполнитьЗначенияСвойств(Строка, ДанныеПотока);
Строка.Статус = "Завершено";
КонецЕсли;
КонецЕсли;
П = Новый Структура("Статус", "");
ДанныеСтроки = Данные.НайтиСтроки(П);
Если ДанныеСтроки.Количество() > 0 Тогда
Строка = ДанныеСтроки[0];
Строка.Статус = "ВыданоЗадание";
ЗаполнитьЗначенияСвойств(ДанныеПотока, Строка);
Иначе
ДанныеПотока.Статус = "Пустой";
КонецЕсли;
КонецПроцедуры
Процедура ПрочитатьРезультат(ДанныеПотока, Данные)
ДанныеПотока = Данные;
КонецПроцедуры
Для запуска всего этого нужно создать обработку и в форме дописать следующий код:
&НаСервере
Процедура ПростыеЧислаНаСервере()
ВремяНачала = ТекущаяДатаСеанса();
ТаблицаЗаданий = РегистрыСведений.Мьютекс.СоздатьЗаполнитьТаблицуЗаданий(
НачалоИнтервала,
КонецИнтервала,
ДлинаПорции
);
РегистрыСведений.Мьютекс.СоздатьЭкземпляр(0, ТаблицаЗаданий);
МассивПотоков = Новый Массив;
Для НомерПотока = 1 По КоличествоПотоков Цикл
Поток = ФоновыеЗадания.Выполнить(
"ДлительныеРасчеты.ПростыеЧисла",
,
"поток#" + Строка(НомерПотока),
"Поиск простых числел"
);
МассивПотоков.Добавить(Поток);
КонецЦикла;
Пока Истина Цикл
МассивПотоков = ФоновыеЗадания.ОжидатьЗавершенияВыполнения(МассивПотоков);
ВсеЗаданияЗавершены = Истина;
Для Каждого Поток Из МассивПотоков Цикл
Если Поток.Состояние = СостояниеФоновогоЗадания.Активно Тогда
ВсеЗаданияЗавершены = Ложь;
Прервать;
КонецЕсли;
КонецЦикла;
Если ВсеЗаданияЗавершены Тогда
Прервать;
КонецЕсли;
КонецЦикла;
РегистрыСведений.Мьютекс
.ПолучитьЭкземпляр(0)
.ОбработатьДанныеЭксклюзивно(
"ПрочитатьРезультат",
ТаблицаЗаданий
);
РегистрыСведений.Мьютекс.УдалитьЭкземпляр(0);
ДлительностьВыполнения = ТекущаяДатаСеанса() - ВремяНачала;
Задания.Загрузить(ТаблицаЗаданий); // в реквизит формы
Сообщить("Время выполнения: " + ДлительностьВыполнения + " сек.");
КонецПроцедуры
В конце публикации будет ссылка на скачивание демо-конфигурации, в которой добавлены замеры производительности, в том числе на ожиданиях блокировки.
Запуск и проверка
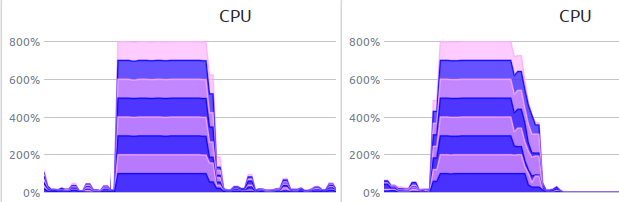
Давайте посмотрим как это работает с различной длиной порций данных (50 и 200):
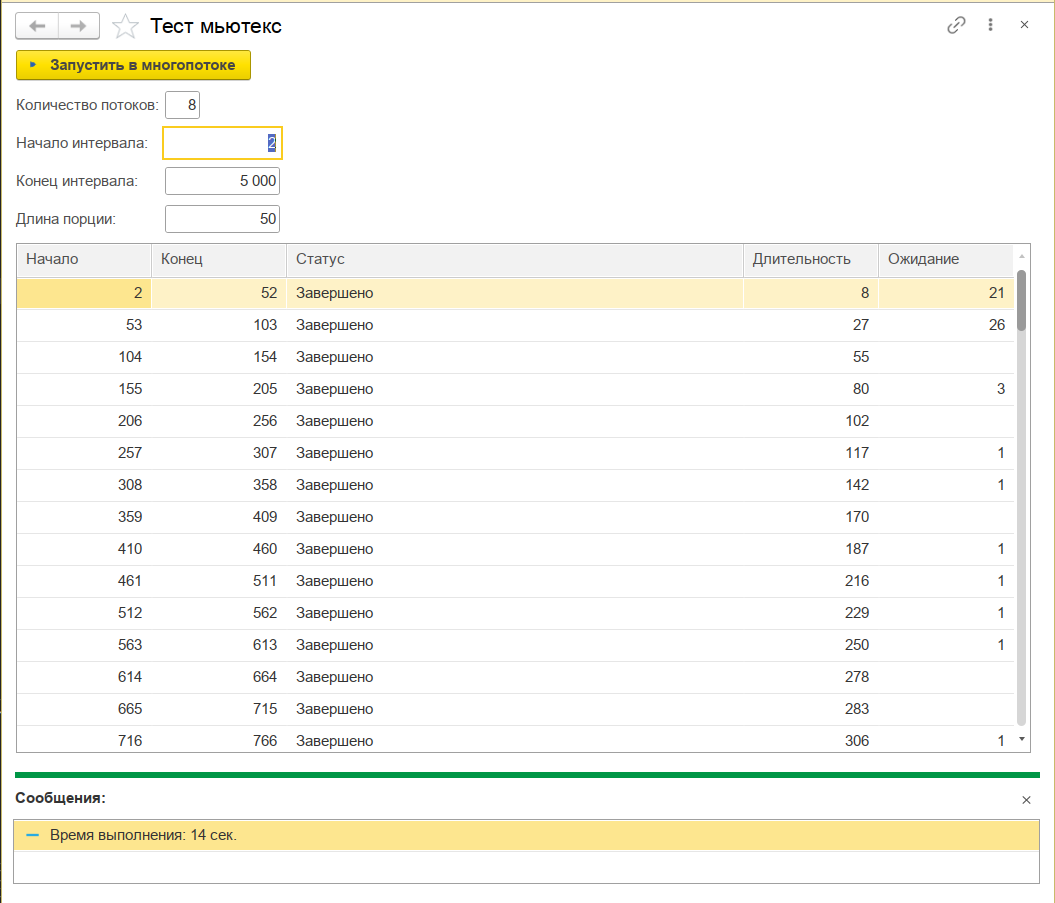
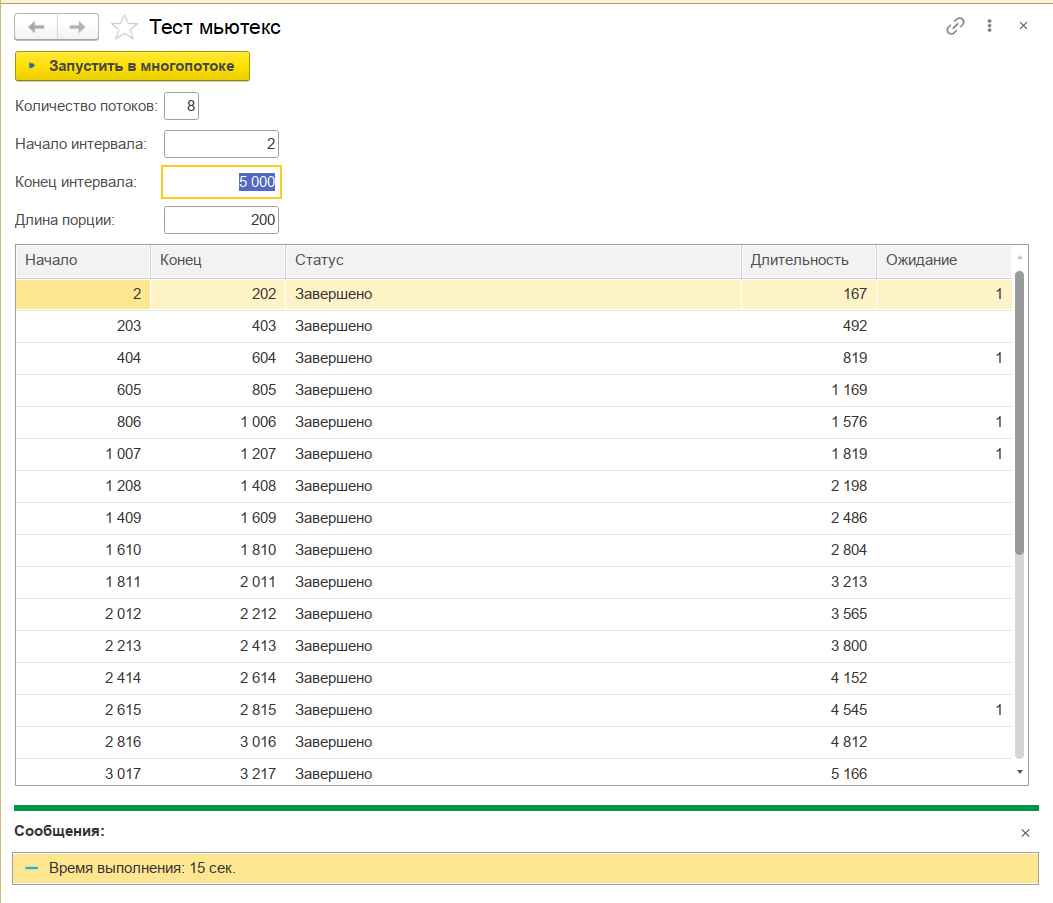
Как видно, при более мелких порциях происходит больше ожидания на блокировках, но вклад этих ожиданий несущественен для общего результата и в целом с более короткой порцией отрабатывает на 1-2 секунду меньше за счет более сбалансированного распределения по ядрам. Левый график для порции 50, правый - 200:
Желающие могут самостоятельно убедиться с помощью счётчиков производительности, что всплеска дисковых операций не происходит - весь интенсивный обмен происходит в кэше - оперативной памяти сервера. Естественно, при прикладной разработке нужно подбирать длину порции таким, чтобы время его обработки существенно превышало время обмена данными (т.н. "амортизация стоимости").